What Is Datature Vi?
Datature Vi is a VLMOps platform for building, training, and deploying custom vision-language models on your own data.
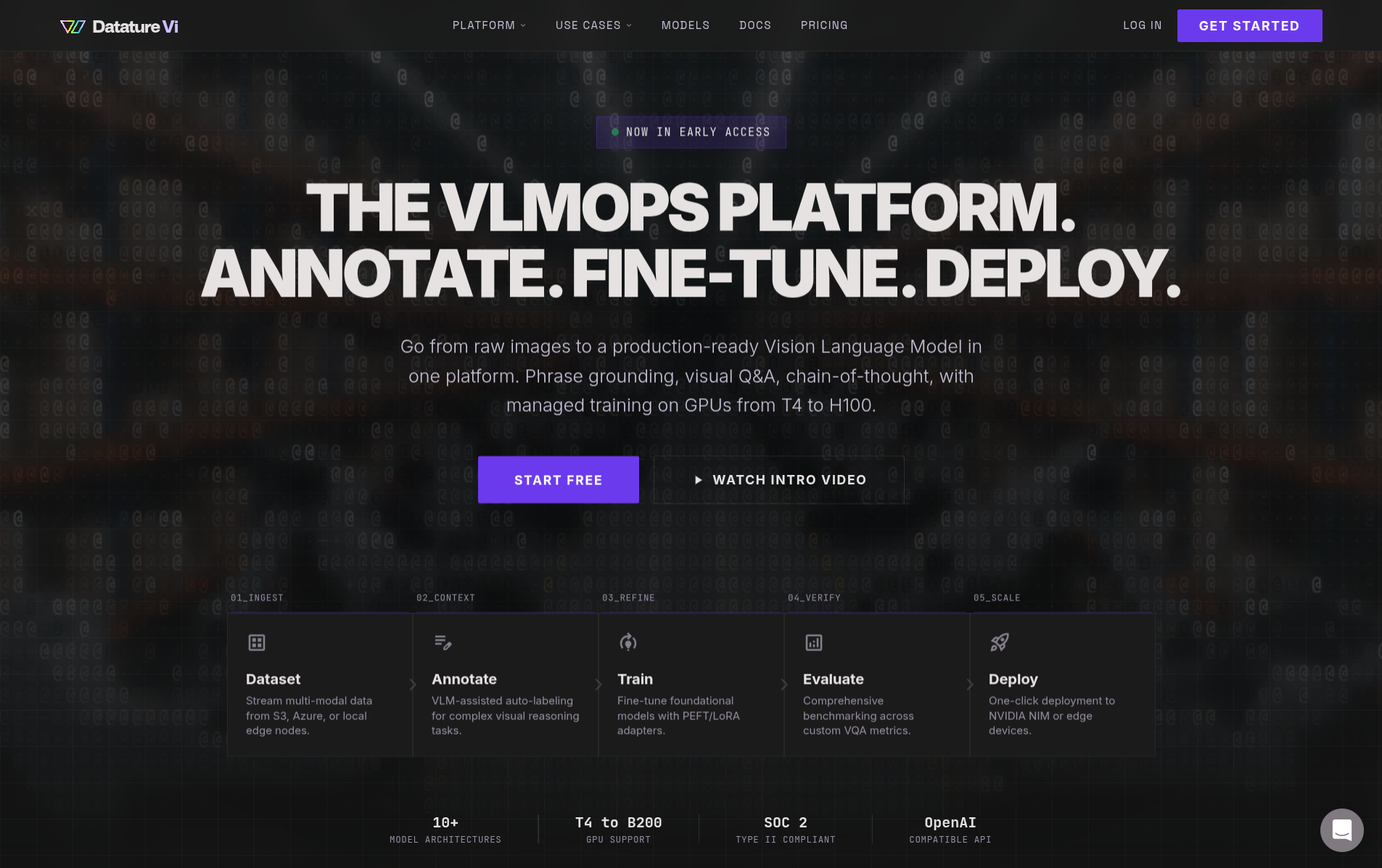
Datature Vi is a VLMOps platform for building custom vision-language models (VLMs) trained on your own data. You upload images, annotate them, fine-tune a VLM, and deploy it with the Vi SDK or NVIDIA NIM containers. Vi manages the GPU infrastructure and training pipeline so you can focus on your data.
You show Vi a few dozen labeled images of what you want it to find or answer, and Vi trains an AI model that can do the same thing on new images automatically. No coding required to get started.
Not sure where to begin? Follow the 30-minute quickstart.
Why build a custom model instead of using ChatGPT or Gemini?
General-purpose AI models can describe images, but production workflows need results that are reliable, consistent, and specific to your domain.
What is a vision-language model?
A VLM takes an image and a text prompt as input and produces a text response. Traditional CV models detect objects from a fixed category list. VLMs understand both the image and what you're asking about it, in natural language.
For a full breakdown of how VLMs work, see What Are Vision-Language Models?.
What problems can Datature Vi solve?
Any task where a person looks at an image and makes a judgment call is a candidate for a custom VLM. Datature Vi supports three types of visual task, each suited to a different class of problem.
How does the workflow work?
You bring images and domain knowledge. Vi handles GPU infrastructure, training, and export. The four-step workflow:
Key terms in plain language
If you are new to AI and VLMs, here are the terms you will see most often in these docs. Each is explained without technical jargon.
For a full glossary, see the searchable glossary.
Who is Datature Vi for?
See it in action
These end-to-end guides walk through real industry workflows, from image collection to running inference. Each one is written for domain teams, not data scientists.
Choose your starting point
Updated 4 months ago