Configure Your Dataset
Set the train-test split ratio and shuffle settings for your VLM training workflow in Datature Vi.
- A workflow open in the workflow canvas
- A dataset with annotations in your Datature Vi organization
- At least 20 annotated images (100+ recommended for production)
Dataset configuration controls two things: which data is used for training and how it is divided between training and validation. Getting this right affects how accurately you can measure model performance on data the model has never seen.
Open dataset configuration
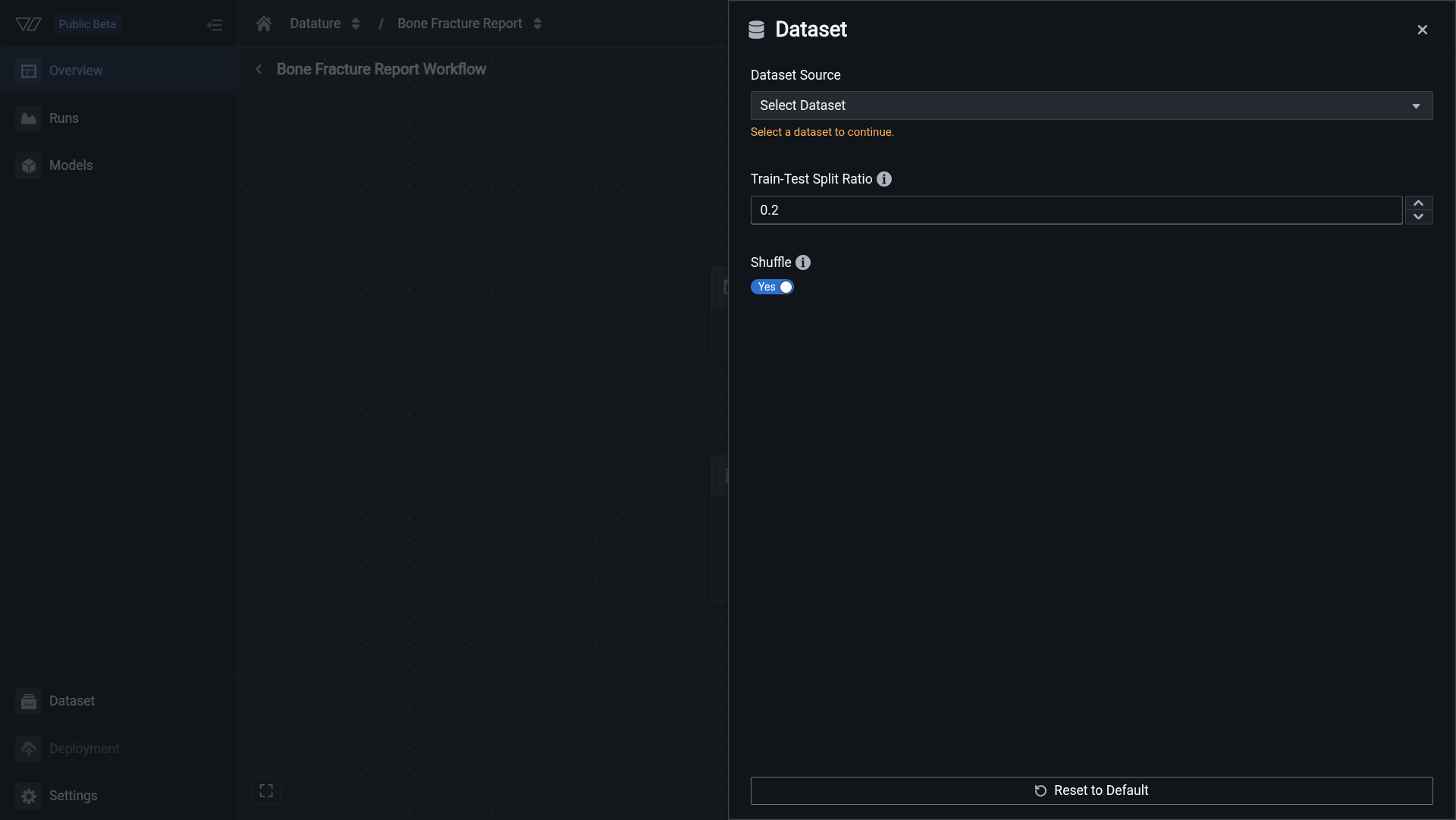
In the workflow canvas, click the Dataset node. The configuration panel opens on the right with a dataset selector, split ratio input, and shuffle toggle.
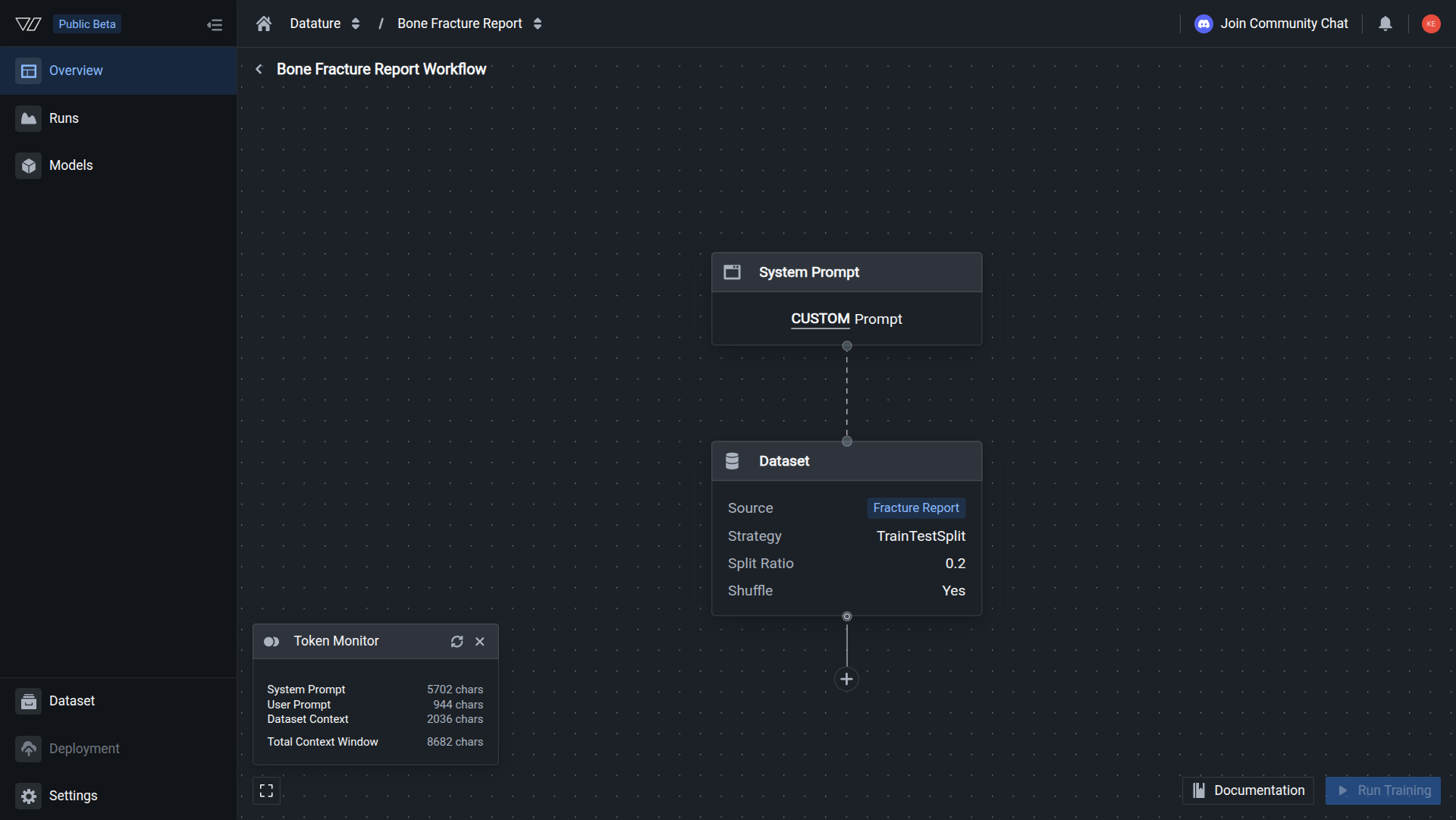
The Dataset node shows your dataset name, split ratio, and shuffle setting. No warning icons are visible on the node.
Train-validation split ratio
When you train a model, not all of your data should be used for training. A portion is held back as a validation set, images the model never sees during training, so that loss and accuracy metrics reflect real generalization rather than memorization of training examples.
The split ratio controls what fraction of your dataset becomes the validation set. A value of 0.2 means 20% of images are reserved for validation and 80% are used for training.
Despite the label sometimes appearing as "train-test split," this is a train-validation split. The validation set is used during the training run to evaluate the model at each checkpoint. It is not a held-out test set for post-training evaluation.
Choosing a ratio by dataset size:
For very small datasets, keep the ratio low (0.1) so the model has enough training examples. For larger datasets, a higher ratio gives more reliable validation metrics without meaningfully reducing training data.
Shuffle
Shuffle randomizes the order of your dataset before the train-validation split is applied.
Without shuffle, the split is positional: the first 80% of images become training data and the last 20% become validation data. If your dataset was exported or annotated in a non-random order (for example, all images of one class grouped together), the validation set will not be representative of the full distribution, and your metrics will be misleading.
With shuffle enabled, images are randomly assigned to each split, giving both sets a balanced mix of examples. The split is a simple random split where each image is independently assigned to training or validation based on the split ratio. It is not stratified by class or annotation content.
When to disable shuffle:
- You need to reproduce an exact split for comparison with a previous run and have a fixed random seed.
- Your data is time-series or sequence-ordered and the split must respect temporal boundaries.
Token monitor
Once you have selected a dataset, you can click the Token Monitor button on the bottom left of the workflow canvas to view token usage for your workflow.
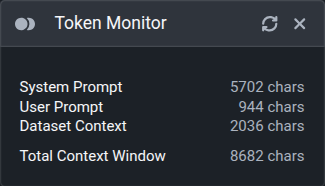
The token monitor reports usage in characters, not model-native tokens. Each model architecture ships with its own tokenizer, so the actual token count will vary depending on which model you select. Treat the character count as a relative sizing guide rather than an exact token budget.
The monitor breaks token usage into three components:
- System Prompt: the instructions that define the model's behavior during training.
- User Prompt: a fixed, generic prompt curated by the Datature team. Customization of this prompt will be available soon.
- Dataset Context: for images, this is the annotation paired with that image. For videos, this is the annotation paired with the frame sequence within that video. Because annotations vary in length across assets, the dataset context value shown is the average token count across all assets in the dataset.
The true token count for a single training step is the sum of the system prompt, user prompt, and the dataset context for that particular asset.
Do this with the Vi SDK
import vi
client = vi.Client(
secret_key="your-secret-key",
organization_id="your-organization-id"
)
flow = client.flows.get("your-flow-id")
blocks = []
for block in flow.spec.blocks:
settings = dict(block.settings)
if block.block.endswith("dataset"):
settings["project"] = "your-new-dataset-project"
settings["projectKind"] = "phrase-grounding"
settings["splitStrategy"] = {
"strategy": "TrainTestSplit",
"splitRatio": 0.2,
"shuffle": True,
"seed": 0
}
blocks.append({
"block": block.block,
"settings": settings,
"style": block.style,
})
client.flows.update(flow_id=flow.flow_id, spec={"blocks": blocks})For more details, see the full SDK reference.