Download Annotations
Export annotation data from your dataset without downloading the asset files.
Downloading annotations exports your label data without the asset files. This gives you a compact file containing phrase grounding annotations (captions, bounding boxes, grounded phrases), visual question answering (VQA) pairs, and dataset metadata. Use this when you need a lightweight backup, want to analyze annotation distribution, or need to convert labels to another format.
- You need a dataset with completed annotations in your Datature Vi workspace.
- Choose your export format before starting: Vi JSONL for human-readable output and general use, TFRecord for TensorFlow training pipelines.
Go to the Annotations tab
Click the Explorer tab in the sidebar, select your dataset, then click the Annotations tab in the Dataset Explorer header. The page displays the Export Annotations section with an Export button.
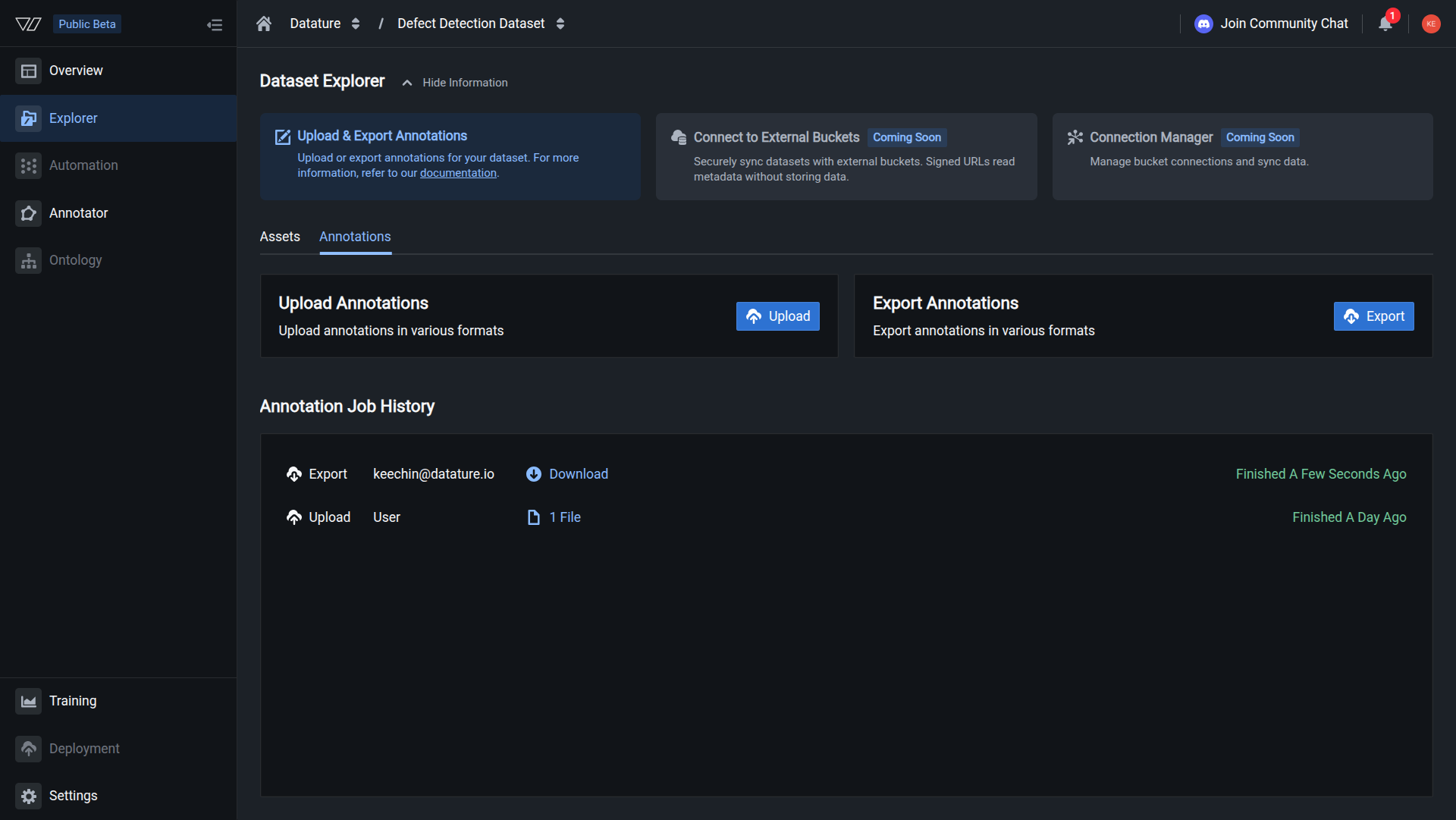
Your dataset is exported when you see a successfully finished job. You can then download the dataset.
Export format
Datature Vi supports two annotation export formats:
Vi JSONL is the default format. It produces a text file where each line is a self-contained JSON object representing one asset and all its annotations. This format is human-readable, easy to parse with any programming language, and works well for data analysis, format conversion, or feeding into custom training pipelines. When you export in Vi JSONL, the asset images are included alongside the annotation file.
TFRecord is a binary format used by TensorFlow training pipelines. Choose this if you plan to train models directly with TensorFlow outside of Datature Vi. TFRecord files are not human-readable but load efficiently during training.
For the complete field specification of the Vi JSONL format, including phrase grounding and VQA record structures, see Upload Annotations.
Test split ratio
When exporting, you can optionally enable Test Split Ratio to divide your exported data into separate training and validation folders. Enter a value between 0.0 and 1.0 for the proportion held back for validation. For example, 0.2 puts 20% of assets into a validation folder and 80% into a train folder.
This is useful when you want to prepare data for training outside of Datature Vi. The split uses random sampling without a fixed seed, so exporting the same dataset twice with the same ratio may produce different splits. If you need a reproducible split, export once and store the result.
Normalized coordinates
When you enable the Normalized option, bounding box coordinates are converted from pixel values to values between 0 and 1, relative to the image dimensions. For example, a box at pixel position (100, 200) on a 1000x800 image becomes (0.1, 0.25). Normalized coordinates are portable across different image resolutions and are the standard input format for most model training frameworks.
Track your export in job history
The Annotation Job History section shows all export operations:
- Job type: Export
- User: Who started the export
- Status: In Progress, Finished, or Failed
Vi JSONL format
Vi JSONL files contain one JSON object per line. Each record covers one asset and all its annotations. A record includes an asset_id string, a filename matching the uploaded image, and an annotations array containing the annotation data for that asset.
For the complete field specification including phrase grounding and VQA record formats, see Upload Annotations.
Troubleshooting
Do this with the Vi SDK
import vi
client = vi.Client(
secret_key="your-secret-key",
organization_id="your-organization-id"
)
result = client.annotations.download(
dataset_id="your-dataset-id",
save_dir="./annotations"
)
print(result.summary())For more details, see the full SDK reference.