Configure Your Model
Choose a VLM architecture and tune training settings for your use case in Datature Vi.
- A workflow open in the workflow canvas
- A configured dataset with train-test split set
- A rough idea of your accuracy and speed requirements
Model configuration in Datature Vi has two parts: picking the right architecture for your task, then tuning the training and inference settings. Both happen inside the workflow canvas when you create a workflow.
For Qwen2.5-VL and Qwen3-VL, fine-tuning starts from instruction-tuned *-Instruct checkpoints only (base weights are not used); Qwen3.5 uses the post-trained Qwen3.5-{size} release, not -Base, and other architectures use the single published lines summarized on Model architectures.
Add a model to your workflow
In the workflow canvas, click the plus button below the Dataset nodes. Select a model architecture from the list. The model node appears on the canvas with default settings applied.
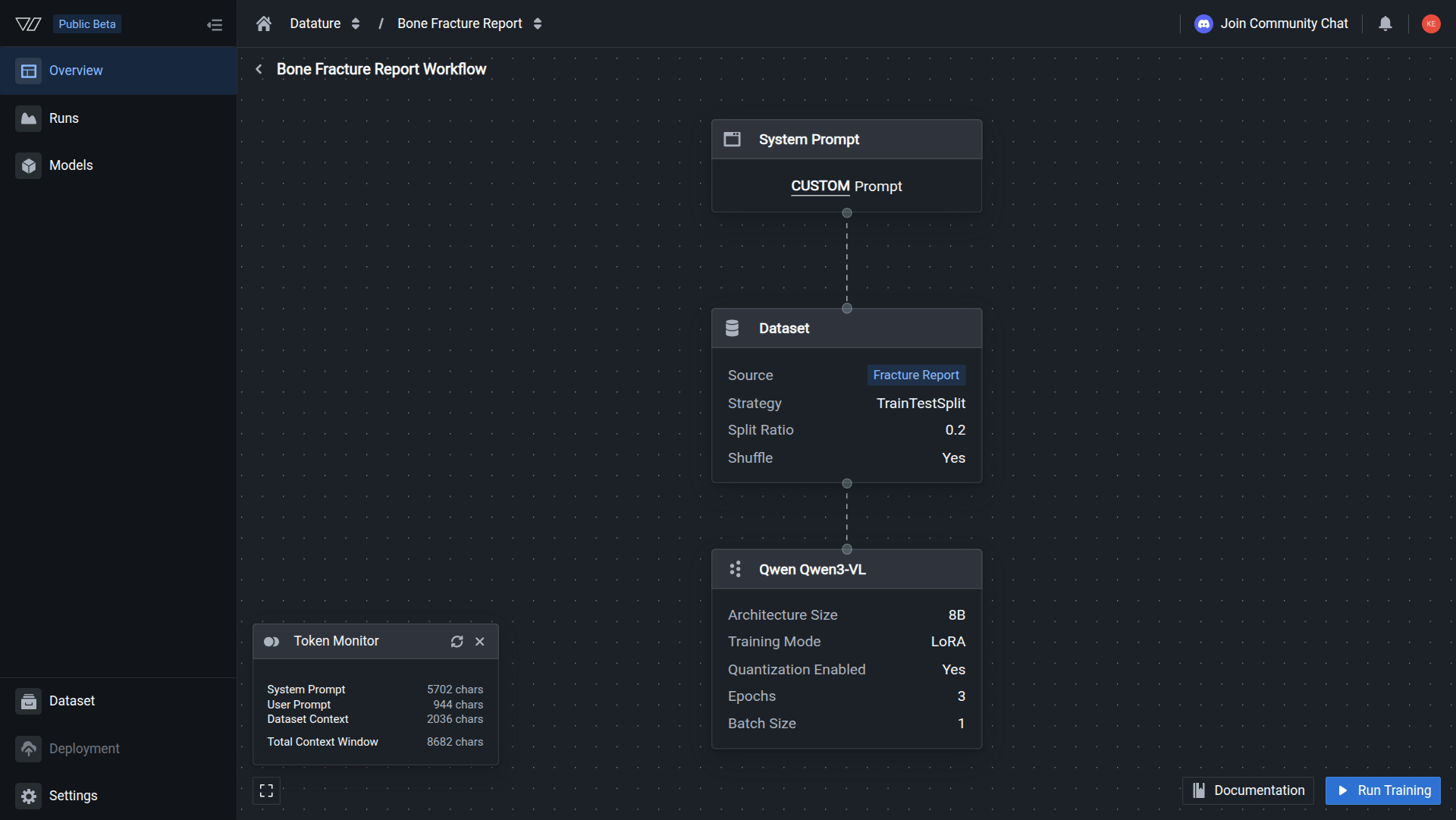
Your architecture selection is complete when the Model node on the workflow canvas displays your chosen architecture and size.
What to configure
QLoRA Training Guide
Understand how quantized LoRA works and configure NF4 or FP4 quantization. The recommended default for most tasks.
Full SFT Training Guide
When and how to use full supervised fine-tuning: hardware requirements, multi-GPU setup, precision options, and when full SFT is worth the cost.
Model Architectures
Compare seven VLMs, modalities and task types, and per-architecture benchmark citations.
Model Settings
Configure training mode, hyperparameters (epochs, learning rate, batch size), and inference behavior (temperature, top-p, repetition penalty).
Quick architecture guide
Use the table below to narrow down your choice before reading the full architecture comparison.
Start with a smaller model (Qwen3.5 4B or Qwen3-VL 4B) to validate your dataset and pipeline with fast iteration cycles. Once your approach is working, scale up to Qwen3.5 9B or larger for production-grade accuracy.
Default vs. custom settings
Datature Vi's default settings work well for most first training runs. Start with defaults and adjust only if you see a specific issue: training not converging, outputs too short, or GPU memory errors.
The settings that move the needle most are:
- Model size: Larger models generally perform better but cost more to train
- Epochs: Too few means underfitting; too many means overfitting
- Learning rate: Affects how fast and how stably the model adapts to your data
- Training mode: LoRA trains faster and uses less memory; full fine-tuning can reach higher accuracy