Download a Model
Generate a Vi SDK download snippet in Datature Vi, then run it locally to pull trained model weights, adapters, and configuration for deployment or offline inference.
Open the Export Model dialog to generate a Python snippet with your credentials filled in. Run that code on your computer and the Vi SDK writes model weights, adapter weights (if you used LoRA fine-tuning), and the training configuration into your local cache. From there you can run inference locally, back up weights, or share the files with your team.
At least one completed training run
New to Datature Vi? Learn what it does or follow the quickstart.
Your organization may still want a documented approver before anyone runs export in production. See Roles and RACI checklist for a lightweight RACI template tied to Vi roles.
Open your training project
Go to Training in the sidebar and click the project containing the model you want to download.
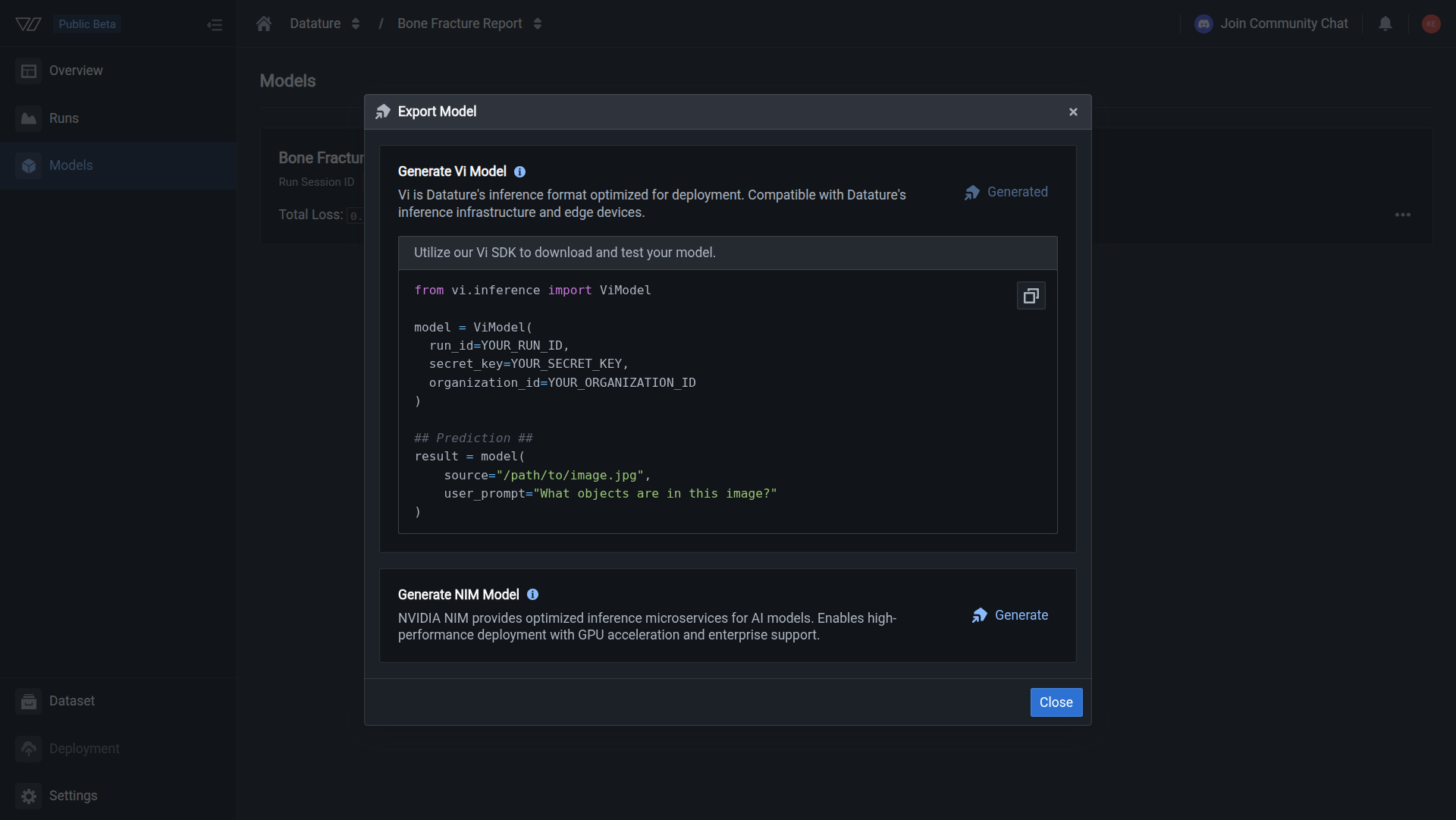
A generated code snippet showing how to download the model using the Vi SDK.
What gets downloaded
When the SDK download finishes, your local cache contains:
Hyperparameters you set in the Vi web app map 1:1 to the hyperparameters object on the model block inside model_full/run.json (same field names and stored values). That file is the saved schema-level record of what ran.
The downloaded directory structure looks like this:
- ~/.datature/vi/models/your-run-id
- model_full
- config.json
- chat_template.json
- generation_config.json
- model.safetensors
- tokenizer.json
- tokenizer_config.json
- vocab.json
- merges.txt
- preprocessor_config.json
- video_preprocessor_config.json
- run.json
- README.md
- model_adapter
- adapter_config.json
- adapter_model.safetensors
- generation_config.json
- run_config.json
The model_full folder contains the base model weights and tokenizer in HuggingFace SafeTensors format. The model_adapter folder contains the LoRA adapter weights, stored separately from the base model. This separation means you can swap adapters without re-downloading the full model, or apply the same adapter to a compatible base model from another source.
When you load a model with the Vi SDK, the adapter is automatically merged with the base weights at load time. If you use the weights outside of the Vi SDK (for example, with vLLM or HuggingFace Transformers directly), load the base model from model_full and apply the adapter from model_adapter using the PEFT library. Models trained with full fine-tuning (not LoRA) will not have a model_adapter folder; all weights are in model_full.
Do this with the Vi SDK
import vi
client = vi.Client(
secret_key="your-secret-key",
organization_id="your-organization-id"
)
downloaded = client.models.download(
run_id_or_link="your-run-id",
save_dir="./models"
)
print(f"Model path: {downloaded.model_path}")For more details, see the full SDK reference.
Deployment options for downloaded models
Once you have the weights locally, you have several paths to production inference:
Downloaded weights are in HuggingFace SafeTensors format, so they load directly into any HuggingFace-compatible serving framework (vLLM, TGI, or custom inference scripts) without conversion.