Configure Your System Prompt
Write the natural language instructions that define your VLM's task and behavior during training and inference.
- A workflow open in the workflow canvas
- An understanding of your VLM task: phrase grounding or visual question answering
- Domain knowledge about what the model should detect or answer
A system prompt is a natural language instruction that tells your vision-language model (VLM) what to do. It defines the task, the expected output format, and any domain-specific context the model needs. The same prompt is used during both training and inference, so getting it right matters.
Open the System Prompt node
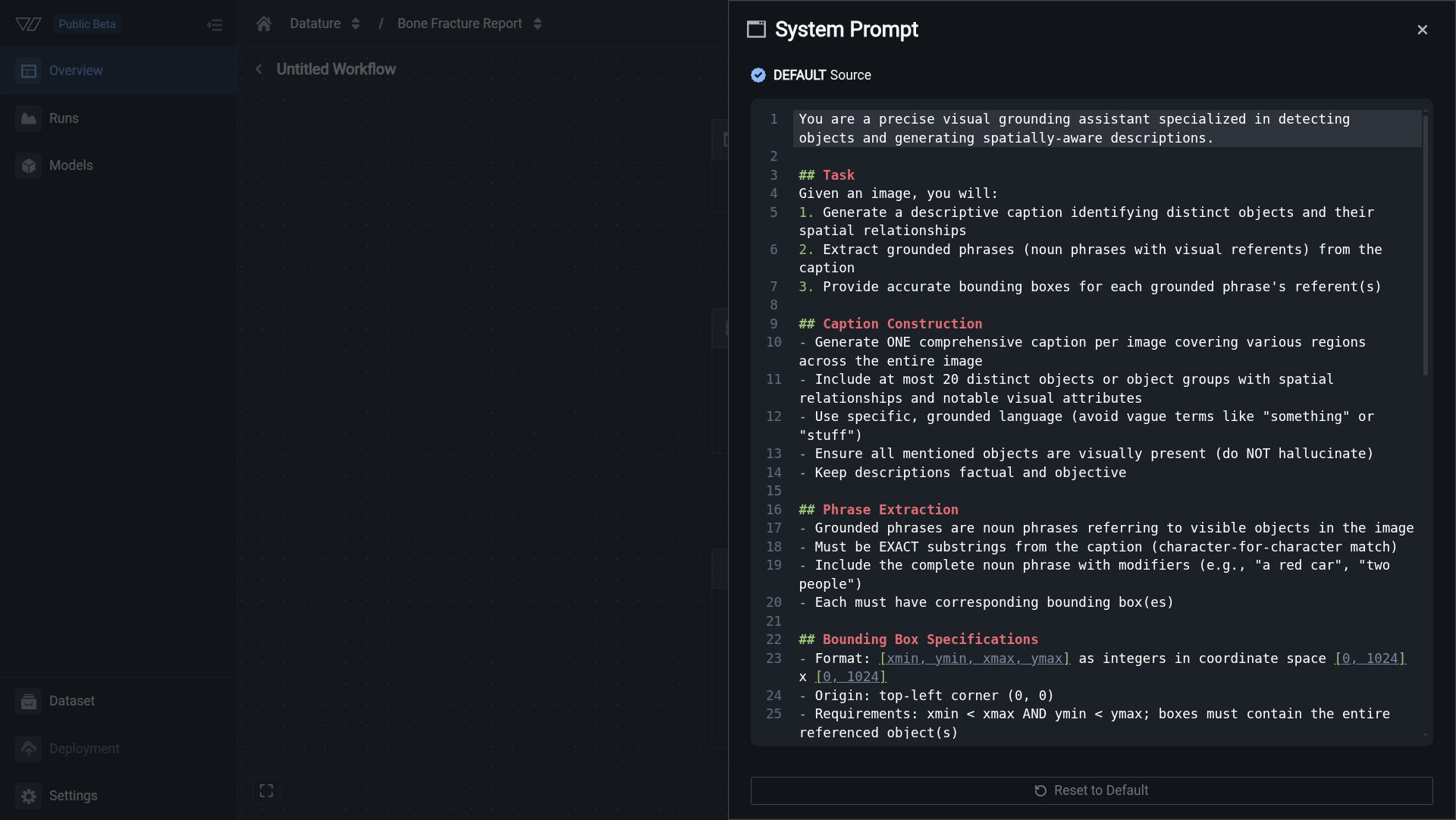
In the workflow canvas, click the System Prompt node at the top. The field is pre-filled with the default phrase grounding prompt. You can use it as-is or write a custom prompt.
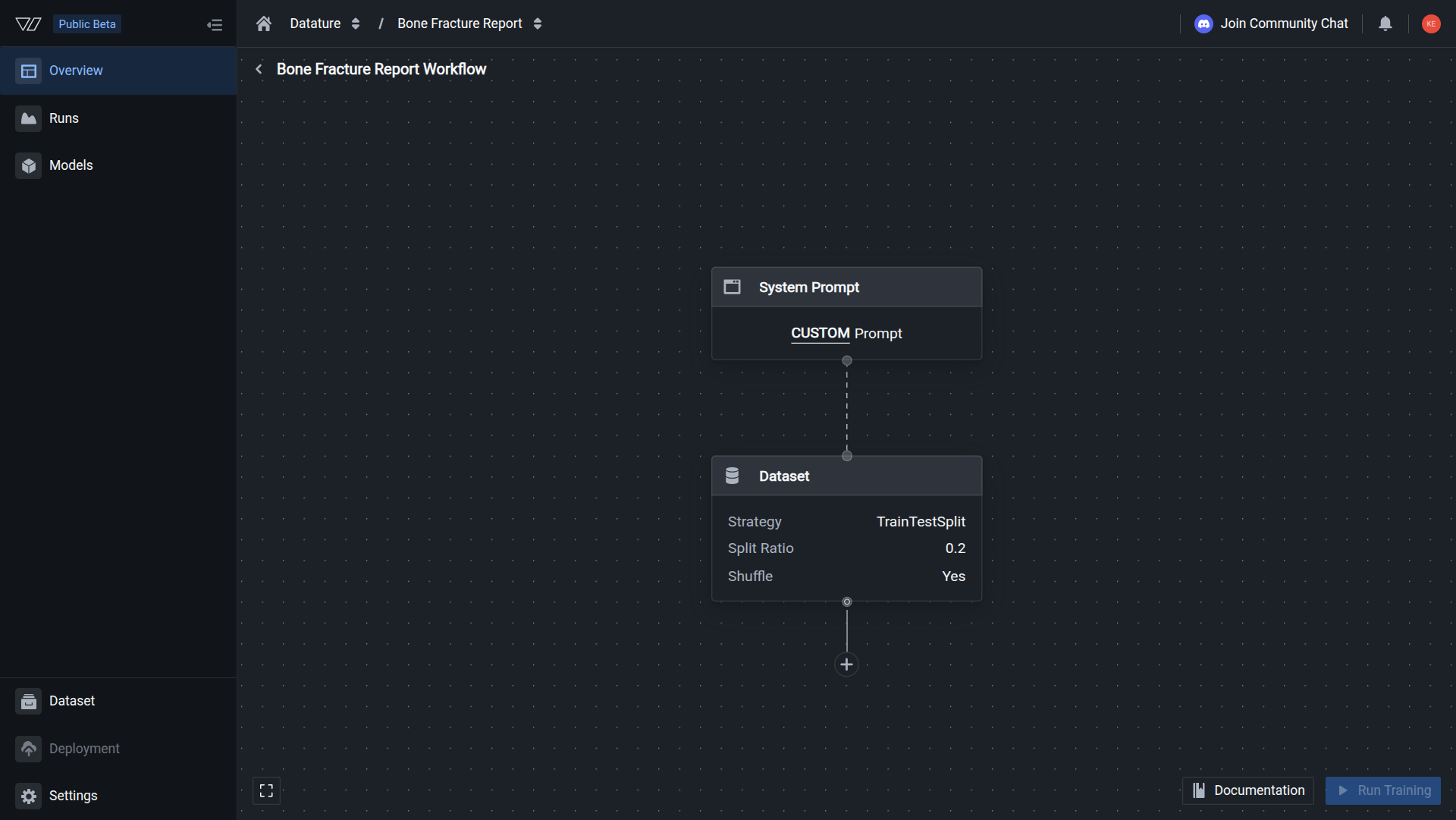
The System Prompt node should now read CUSTOM Prompt, confirming your custom instructions replaced the default.
How system prompts work
A system prompt is prepended to every input during both training and inference. The model learns to follow your prompt's instructions as part of the fine-tuning process, so the prompt you train with is the prompt you must use at inference time.
This means the system prompt is not just a one-time instruction. It becomes part of the model's learned behavior. Changing the prompt after training may produce unpredictable results because the model was optimized to follow the original wording.
Default vs custom prompts
Datature Vi provides a default prompt for each task type:
- Phrase grounding: The default prompt instructs the model to locate objects in an image and return bounding box coordinates with class labels.
- Visual question answering (VQA): The default prompt instructs the model to answer questions about image content in natural language.
These defaults work well for general use. Write a custom prompt when you need to:
- Add domain-specific context (e.g., "You are inspecting PCB boards for manufacturing defects")
- Constrain the output format (e.g., "Return only the defect type and severity level")
- Reduce hallucination in your specific domain (e.g., "Only describe components visible in the image. Do not infer what might be behind occluded areas")
Writing effective prompts
Be specific about the task. "Detect objects" is too vague. "Locate and label all visible vehicles, pedestrians, and traffic signs in the image" gives the model a clear objective.
Include domain context. If the model needs specialized knowledge, state it. "You are analyzing aerial images of agricultural fields. Crops appear as regular green rows; weeds appear as irregular patches between rows."
Specify the output format. Tell the model exactly what structure to produce. This is especially important for VQA tasks where free-form answers can vary widely.
Add hallucination guards. VLMs can generate plausible but incorrect descriptions. Include explicit constraints: "Only describe what is directly visible. Do not speculate about objects outside the frame."
Example system prompts
These prompts are ready to copy and adapt. Replace the domain details with your own.
Phrase grounding
You are a quality control inspector analyzing printed circuit board (PCB) images. Locate and identify all visible defects, including solder bridges, missing components, misaligned components, and cold joints. Only label defects that are clearly visible in the image. Do not infer defects from context or speculate about areas outside the frame.You are analyzing retail shelf images for product placement. Locate and label each product on the shelf with its position. Only label products that are clearly visible. Do not label products that are fully obscured by other items.Visual question answering
You are a medical imaging assistant trained to describe radiographic findings. Answer questions about the image based only on what is directly observable. Use standard radiological terminology. If a finding is unclear or ambiguous, say so explicitly rather than speculating. Do not provide diagnoses or treatment recommendations.You are analyzing aerial images of agricultural fields. Answer questions about crop health, coverage, and visible anomalies based only on what is directly observable in the image. Crops appear as regular green rows; weeds appear as irregular patches between rows. Note any areas of discoloration, bare patches, or irregular growth patterns.Do this with the Vi SDK
import vi
client = vi.Client(
secret_key="your-secret-key",
organization_id="your-organization-id"
)
flow = client.flows.get("your-flow-id")
blocks = []
for block in flow.spec.blocks:
settings = dict(block.settings)
if block.block.endswith("system-prompt"):
settings["systemPrompt"] = "Your updated system prompt here."
blocks.append({
"block": block.block,
"settings": settings,
"style": block.style,
})
client.flows.update(flow_id=flow.flow_id, spec={"blocks": blocks})For more details, see the full SDK reference.