Download Full Dataset
Export your complete dataset including all assets and annotations from Datature Vi for backup, local development, or data migration.
Downloading the full dataset exports all assets (images and videos) together with their annotations in a structured folder. This is the right choice when you need a complete backup, want to train a model locally, or are migrating data to another platform.
- You need an existing dataset in your Datature Vi workspace.
- Make sure you have enough local disk space. A dataset with 1,000 images typically needs 500 MB to 5 GB depending on resolution.
- For datasets over 1,000 assets, the Vi SDK provides more reliable downloads with automatic retry logic.
Go to the Annotations tab
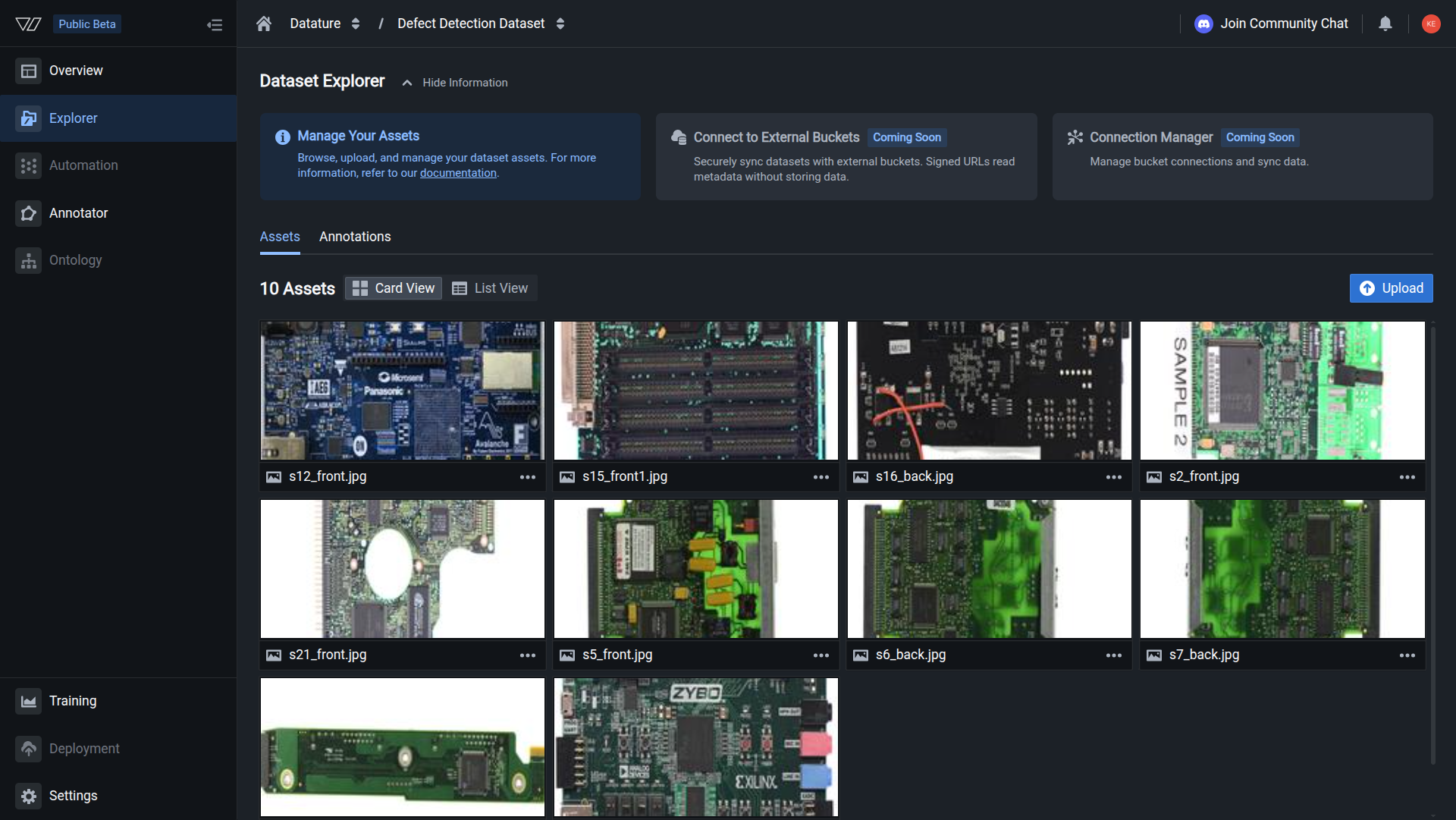
Click the Explorer tab in the sidebar, select your dataset, then click the Annotations tab in the Dataset Explorer header. The page displays the Export Annotations section with an Export button.
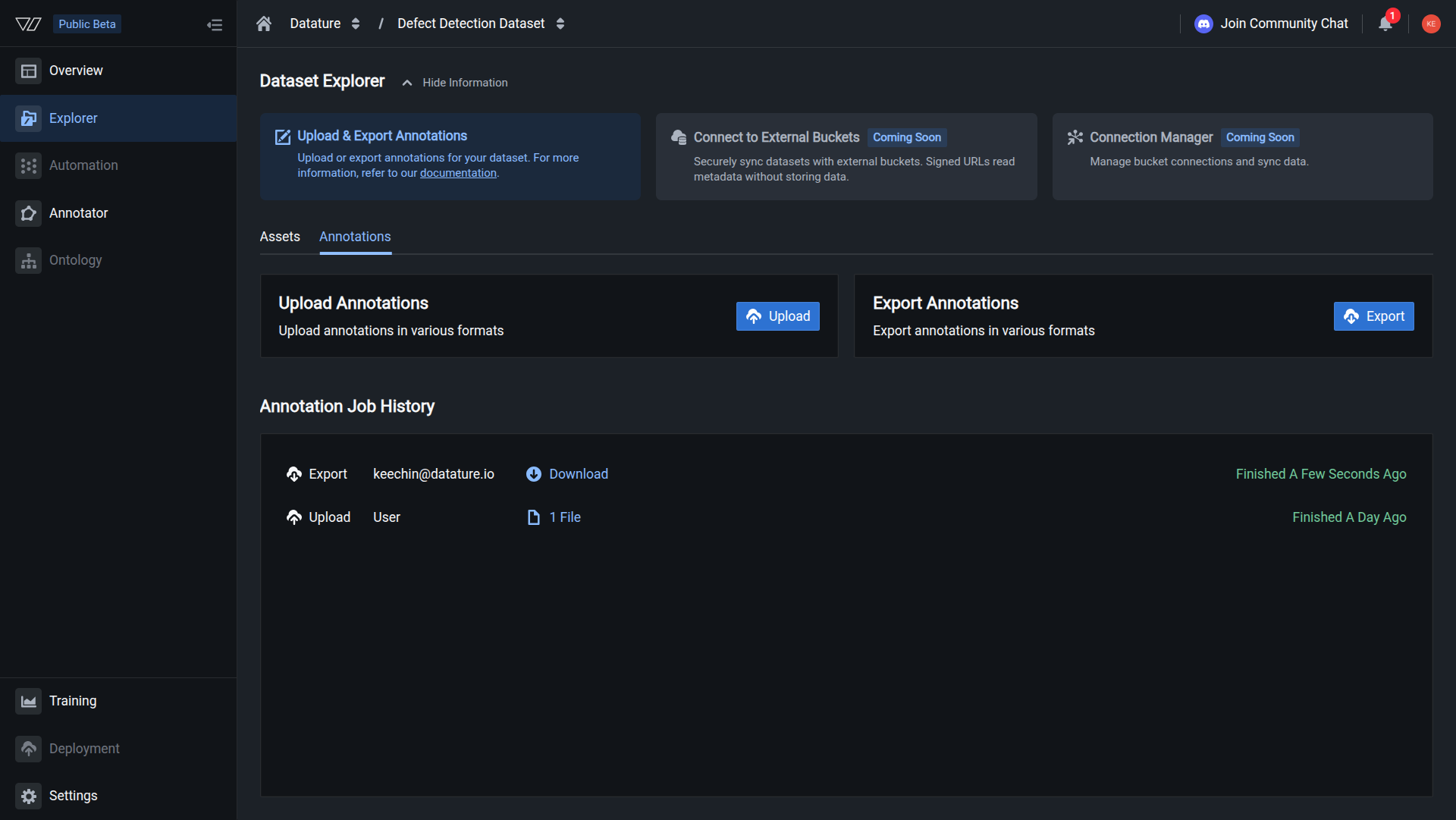
Your dataset is exported when you see a successfully finished job. You can then download the dataset.
Exported folder structure
With train/test split enabled (ratio > 0):
- dataset-name
- train
- images
- image1.jpg
- image2.jpg
- annotations
- image1.jsonl
- image2.jsonl
- test
- images
- image3.jpg
- annotations
- image3.json
- metadata.json
Without split (ratio = 0 or disabled):
- dataset-name
- dump
- assets
- image1.jpg
- image2.jpg
- annotations
- image1.jsonl
- image2.jsonl
- metadata.json
Track your export in job history
The Annotation Job History section shows all export operations:
- Job type: Upload or Export
- Initiated by: Who started the export
- Status: In Progress, Finished, or Failed
Troubleshooting
Do this with the Vi SDK
import vi
client = vi.Client(
secret_key="your-secret-key",
organization_id="your-organization-id"
)
result = client.datasets.download(
dataset_id="your-dataset-id",
save_dir="./data"
)
print(result.summary())For more details, see the full SDK reference.