Kill a Run
Stop an active training session immediately to free GPU resources or abandon a misconfigured run.
Killing a run in Datature Vi stops training immediately. The run status changes to Killed, GPU resources are freed, and training cannot resume from that point. You can review partial metrics and logs, then start a fresh run with corrected settings.
- Killing a run is irreversible.
- Only active runs can be killed (completed, failed, and already-killed runs cannot)
Open your training project
Go to Training in the sidebar and click the project containing the run you want to review.
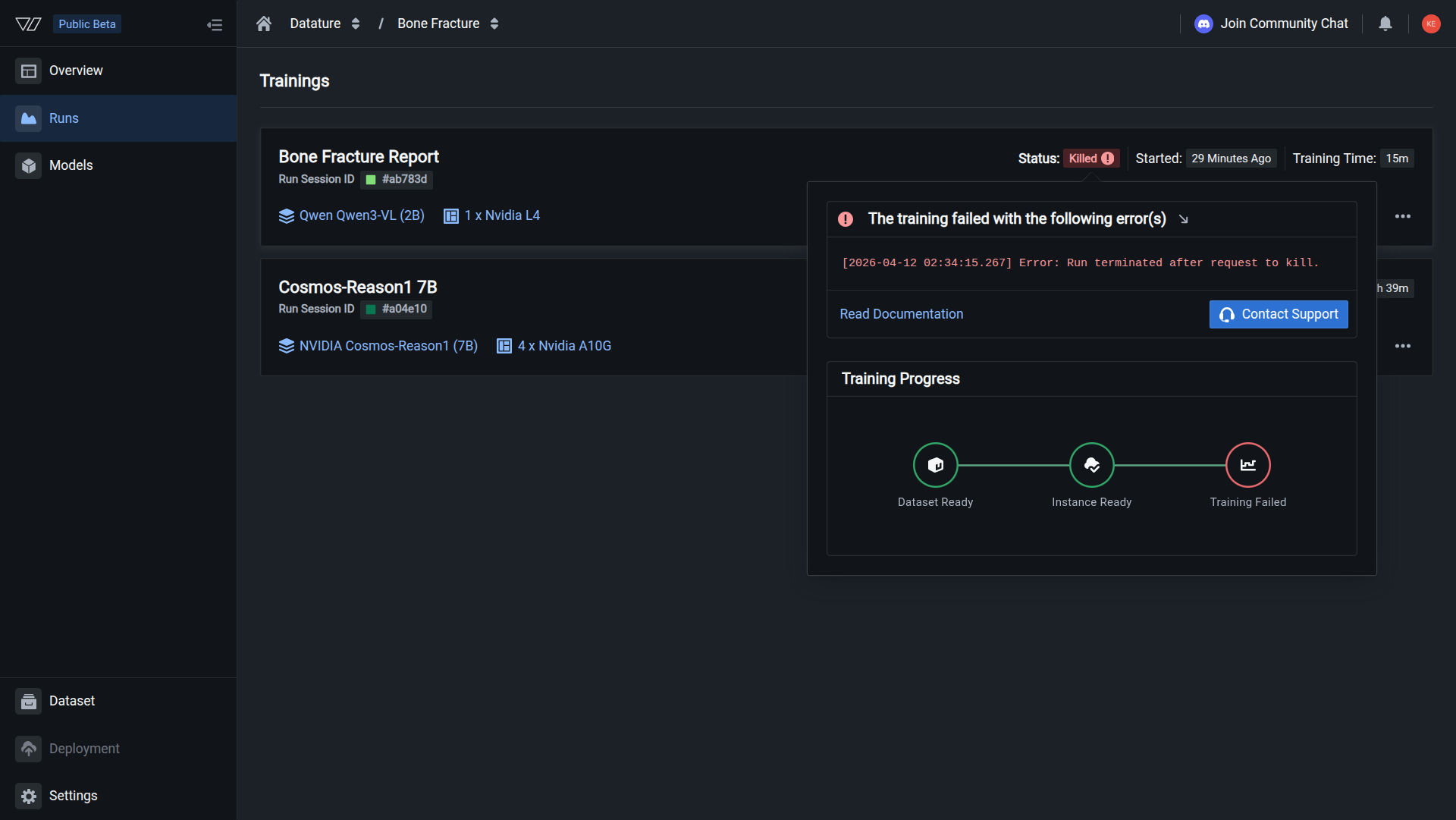
The run shows Killed status in the runs list. Partial metrics and logs remain accessible for review.
After killing a run
Training progress up to the kill point is preserved: you can still open the run to read partial loss charts and logs. Use that information to diagnose what went wrong before starting a new run.
Common reasons to kill and what to fix:
- Wrong dataset selected: Update the workflow's dataset configuration before restarting.
- Out-of-memory error: Reduce the batch size or select a GPU with more memory.
- Loss not decreasing: Review the system prompt and training parameters; consider a different model architecture.
- Wrong workflow started: Start a new run with the correct workflow.
Once you have noted what you need, delete the killed run to keep the runs list clean.
Do this with the Vi SDK
import vi
client = vi.Client(
secret_key="your-secret-key",
organization_id="your-organization-id"
)
run = client.runs.kill(run_id="your-run-id")
print(f"Run killed at: {run.spec.killed_at}")For more details, see the full SDK reference.